WriteBot: An AI-Powered Handwriting Synthesis Platform
A fully operational web application capable of transforming digital text into photorealistic handwritten SVG documents in under five seconds, at enterprise scale, with batch processing, role-based access, and extensible character customization
Key Outcomes
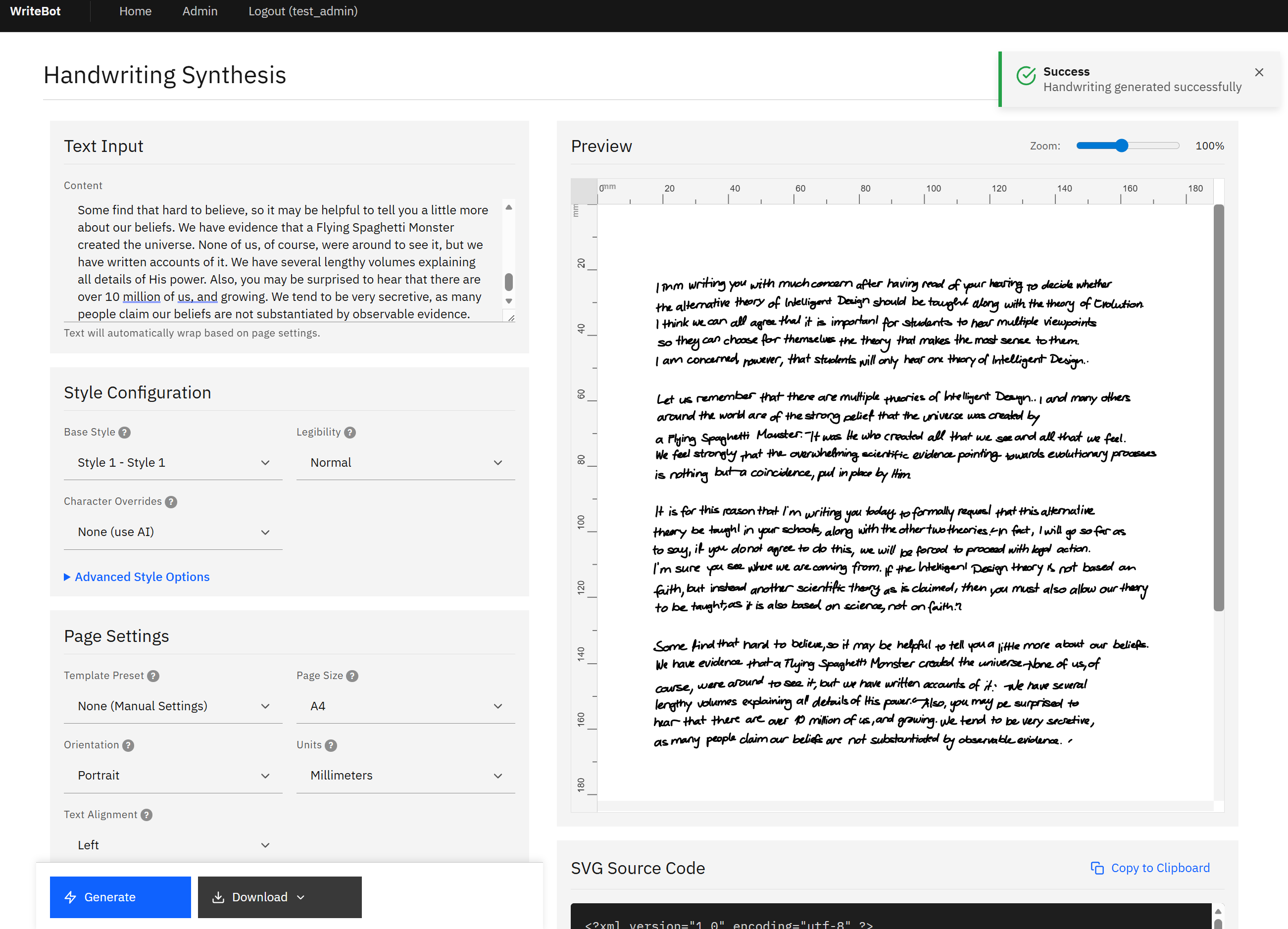
- Performance — Single document generation completes in two to five seconds with GPU acceleration, representing an order-of-magnitude improvement over CPU-only inference. Chunked generation handles documents of twenty or more lines in three to eight seconds without quality degradation.
- Generation Quality — The RNN produces stroke sequences with natural variation in pressure, speed, and spacing. Output passes casual visual inspection as human-written, with twelve style options providing sufficient diversity for varied use cases.
- Scale — The batch processing pipeline handles CSV and XLSX uploads with per-row personalization, enabling high-volume document generation with individual customization. The job queue system supports scheduled execution and progress monitoring for large-scale runs.
- Operational Readiness — The platform includes comprehensive administration capabilities, activity monitoring, usage tracking, health checks, and automated deployment — reducing ongoing operational overhead to routine maintenance.
- Extensibility — The character override system, template preset architecture, and modular codebase provide clear extension points for future capabilities without requiring modifications to the core generation engine.
The Challenge
In an era of digital saturation, organizations face a paradox: the more sophisticated their communication technology becomes, the less personal it feels. Mass emails are ignored. Printed mailers are discarded. Generic digital outreach is filtered into oblivion.
Handwritten communication, by contrast, commands attention. Research consistently demonstrates that handwritten notes achieve open rates and engagement multiples far exceeding their digital counterparts. Yet the obvious constraint has always been scale — authentic handwriting cannot be produced at volume through conventional means.
Our client identified this gap as a strategic opportunity: build an AI system that generates genuinely realistic handwritten documents, indistinguishable from human output, and make it available as a scalable, enterprise-ready web platform. The challenge was not merely technical. It demanded the intersection of deep learning research, production software engineering, and a nuanced understanding of what makes handwriting look and feel human.
They engaged our firm to architect, build, and deploy this system from the ground up.
Our Approach
We structured the engagement around four workstreams, executed in overlapping phases to compress the delivery timeline while maintaining architectural coherence.
The Core
The foundation of the platform is a recurrent neural network built on TensorFlow, employing LSTM cells with a learned attention mechanism. The model was trained on the IAM Handwriting Dataset, a corpus of handwriting samples that provides the diversity necessary for realistic synthesis.
The generation pipeline operates in a sequence of deliberate steps. When a user submits text, the system first normalizes the input, stripping diacritical marks and filtering characters to those within the model’s trained vocabulary. The text is then passed to the RNN, which generates stroke sequences, not rendered characters, but the actual pen trajectory data that a human hand would produce. This distinction is critical: the system does not assemble pre-drawn letters, it writes them, stroke by stroke, with the probabilistic variation inherent in human motor control.
We implemented a two-pass SVG rendering system to handle page layout with precision. The first pass calculates the spatial requirements of the generated strokes, determining line breaks, page breaks, and alignment. The second pass renders the final SVG output with configurable margins, page sizes, and formatting parameters. This separation ensures that layout decisions are informed by the actual dimensions of generated content, not by estimates.
To address quality degradation on longer texts — a known limitation of sequential RNN inference — we developed an adaptive chunking strategy. The system intelligently segments input text at natural boundaries, generates each chunk independently, and composites the results into a seamless document. This preserves stroke quality regardless of document length.
The Web Application and API
We designed the application layer as a modular Flask application with clearly separated concerns, organized into dedicated blueprints for generation, batch processing, job management, administration, and authentication.
The real-time generation API accepts configuration parameters encompassing text content, handwriting style, page dimensions, margins, alignment, stroke properties, and legibility mode. The parameter space is extensive with over thirty configurable attributes, yet the API surface is clean, with sensible defaults and a preset system that allows administrators to create reusable template configurations.
For high-volume use cases, the batch processing system accepts CSV and XLSX file uploads, iterating through rows to generate individualized handwritten documents. This operates in two modes: a synchronous streaming mode using Server-Sent Events for smaller batches requiring immediate feedback, and an asynchronous queued mode powered by Celery for larger jobs that can be scheduled and monitored independently.
The job queue system provides full lifecycle management: creation, scheduling, progress monitoring, cancellation, and result retrieval. Completed batch results are packaged as ZIP archives and made available through time-limited signed URLs with a two-hour expiry window, ensuring secure distribution without persistent public endpoints.
Security, Access Control, and Observability
The platform implements a defense-in-depth security model appropriate for an enterprise application handling potentially sensitive document content.
Authentication is managed through Flask-Login with secure password hashing via Werkzeug. Role-based access control distinguishes between standard users and administrators, with the admin role governing access to user management, template configuration, character override administration, and the activity dashboard.
API security includes rate limiting backed by Redis, enforcing configurable thresholds at both daily and hourly granularity. All user actions are recorded in a structured activity log, and daily usage statistics are aggregated for capacity planning and audit purposes.
The network architecture leverages Cloudflare Tunnel for secure external access, eliminating the need to expose application ports directly to the internet. Internal service communication is isolated within a dedicated subnet, with TLS termination handled at the Cloudflare edge.
For observability, the platform integrates Sentry for error tracking across both the Flask application and Celery workers, provides a health check endpoint reporting component status (application, database, Redis, Celery), and supports structured logging. An optional Flower dashboard provides real-time visibility into Celery task processing.
Infrastructure and Deployment
The deployment architecture was designed for the client’s Proxmox virtualization environment, with a topology that balances performance, isolation, and operational simplicity.
The core application consisting of a Flask web server, aCelery worker, and a Celery Beat scheduler — runs within Docker containers on a QEMU virtual machine provisioned with 16 GB RAM, 8 CPU cores, and GPU passthrough. The VM-based approach was a deliberate architectural decision: TensorFlow GPU acceleration requires PCI passthrough, which is not supported by LXC containers.
PostgreSQL and Redis each run in dedicated LXC containers with resource allocations proportional to their workloads, 2 GB and 512 MB of RAM, respectively. This separation provides both resource isolation and security boundaries between the data tier and application tier.
We automated the entire provisioning and deployment process through purpose-built scripts covering Proxmox host configuration, LXC container creation, PostgreSQL and Redis setup, Docker VM provisioning with GPU passthrough, and application deployment via Docker Compose. The production Docker image is built against NVIDIA’s CUDA 12.8 and cuDNN 9.3 base images, ensuring optimal GPU utilization.